
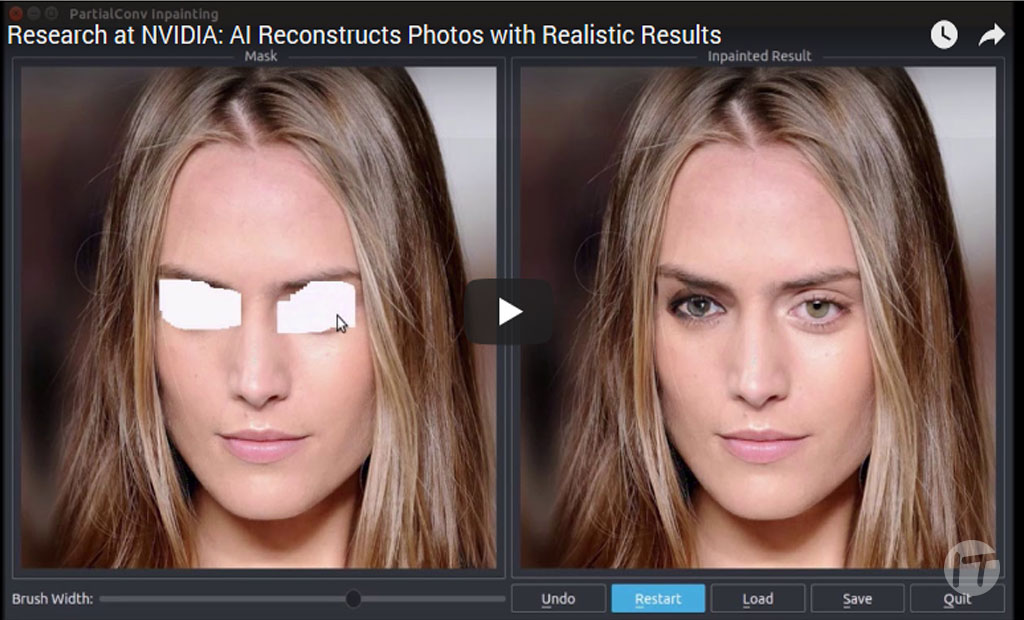
Investigadores de NVIDIA, dirigidos por Guilin Liu, introdujeron un método de aprendizaje profundo que puede editar imágenes o reconstruir una imagen dañada, ya sea si está perforada o le faltan píxeles.
El método también se puede usar para editar imágenes eliminando el contenido y rellenando las perforaciones resultantes.
El método, que realiza un proceso llamado “impainting de imagen”, podría implementarse en softwares de edición fotográfica para eliminar el contenido no deseado y reemplazarlo con una alternativa realista generada por computadora.
“Nuestro modelo puede manejar con solidez orificios de cualquier forma, tamaño de ubicación o distancia de los bordes de la imagen. Los enfoques previos de aprendizaje profundo se han centrado en regiones rectangulares alrededor del centro de la imagen, y con frecuencia dependen del costoso procesamiento posterior “, declararon los científicos de NVIDIA en su trabajo de investigación. “Además, nuestro modelo maneja a la perfección orificios de mayor tamaño”. Para comenzar a entrenar su red neuronal, el equipo primero generó 55.116 máscaras de rayas aleatorias y agujeros de formas y tamaños arbitrarios. También generaron casi 25.000 otras máscaras para realizar pruebas. Estos se identificaron en seis categorías según los tamaños relativos a la imagen de entrada, con el fin de mejorar la precisión de la reconstrucción.
Un ejemplo de las máscaras generadas para el entrenamiento.
Utilizando las GPU NVIDIA Tesla V100 y el marco de aprendizaje profundo PyTorch acelerado por cuDNN, el equipo entrenó su red neuronal aplicando las máscaras generadas a las imágenes de los conjuntos de datos ImageNet, Places2 y CelebA-HQ.
Durante la fase de entrenamiento, se introducen agujeros o partes faltantes en imágenes de entrenamiento completas de los conjuntos de datos anteriores, para permitir que la red aprenda a reconstruir los píxeles faltantes.
Los investigadores dijeron que los métodos existentes de impainting para imágenes basados en el aprendizaje profundo sufren porque el valor resultante para los píxeles faltantes necesariamente depende del valor de la entrada que se debe suministrar a la red neuronal para completarlos. Esto conduce a artefactos como discrepancias de color y borrosidad en las imágenes.
Para solucionar este problema, el equipo de NVIDIA desarrolló un método que garantiza que los valores resultantes de los píxeles faltantes no dependan del valor de entrada proporcionado para esos píxeles. Este método usa una capa de “convolución parcial” que re-normaliza cada resultado dependiendo de la validez de su campo receptivo correspondiente. Esta re-normalización asegura que el valor resultante sea independiente de los valores de los píxeles faltantes en cada campo receptivo.
El modelo se construye a partir de una arquitectura UNet implementada con estas convoluciones parciales. Un conjunto de funciones de pérdida, la coincidencia de pérdidas de características con un modelo VGG, así como las pérdidas de estilo, se utilizaron para capacitar al modelo para producir resultados realistas. Debido a esto, el modelo supera los métodos anteriores, aseguró el equipo.
“A nuestro saber y entender, somos los primeros en demostrar la eficacia de la imagen de aprendizaje profundo en modelos de impainting para orificios de forma irregular”, mencionaron los investigadores de NVIDIA.
Los investigadores también expresaron en el documento que pueden aplicar el mismo marco para manejar tareas de super-resolución de imágenes.
Aprende más sobre las investigaciones de NVIDIA y cómo el ecosistema de aprendizaje profundo de NVIDIA está equipando a investigadores y desarrolladores para concretar avances de aprendizaje profundo e inteligencia artificial.

